This guide is targeted to people that want to write new features or fix bugs in rmlint.
We try to adhere to some principles when adding features:
rmlint modify the filesystem itself, only produce output
to let the user easily do it.Also keep this in mind, if you want to make a feature request.
The code is hosted on GitHub, therefore our preferred way of receiving patches is using GitHub's pull requests (normal git pull requests are okay too of course).
Note
origin/master should always contain working software. Base your patches
and pull requests always on origin/develop.
Here's a short step-by-step:
git checkout develop && git checkout -b my_feature)git commit -am "Fixed it all.")git commit --amend)git push origin my_feature)Here are some other things to check before submitting your contribution:
Does your code look alien to the other code? Is the style the same? You can run this command to make sure it is the same:
$ clang-format -style=file -i $(find lib src -iname '*.[ch]')
Do all tests run? Go to the test documentation for more info. Also after opening the pull request, your code will be checked via TravisCI.
Is your commit message descriptive? whatthecommit.com has some good examples how they should not look like.
Is rmlint running okay inside of valgrind (i.e. no leaks and no memory violations)?
For language-translations/updates it is also okay to send the .po files via
mail at sahib@online.de, since not every translator is necessarily a
software developer.
rmlint has a not yet complete but quite powerful testsuite. It is not
complete yet (and probably never will), but it's already an valueable boost of
confidence in rmlint's correctness.
The tests are based on nosetest and are written in python>=3.0.
Every testcase just runs the (previously built) rmlint binary a
and parses it's json output. So they are technically blackbox-tests.
On every commit, those tests are additionally run on TravisCI.
The behaviour of the testsuite can be controlled by certain environment variables which are:
RM_TS_DIR: Testdir to create files in. Can be very large with some tests,
sometimes tmpfs might therefore slow down your computer. By default
/tmp will be used.RM_TS_USE_VALGRIND: Run each test inside of valgrind's memcheck. (slow)RM_TS_USE_GDB: Run tests inside of gdb. Fatal signals will trigger an
backtrace.RM_TS_PEDANTIC: Run each test several times with different optimization options
and check for errors between the runs. (slow).RM_TS_SLEEP: Waits a long time before executing a command. Useful for
starting the testcase and manually running rmlint on the priorly generated
testdir.RM_TS_PRINT_CMD: Print the command that is currently run.RM_TS_KEEP_TESTDIR: If a test failed, keep the test files.Additionally slow tests can be omitted with by appending -a '!slow' to
the commandline. More information on this syntax can be found on the nosetest
documentation.
Before each release we call the testsuite (at least) like this:
$ sudo RM_TS_USE_VALGRIND=1 RM_TS_PRINT_CMD=1 RM_TS_PEDANTIC=1 nosetests-3.4 -s -a '!slow'
The sudo here is there for executing some tests that need root access (like
the creating of bad user and group ids). Most tests will work without.
To see which functions need more testcases we use gcov to detect which lines
were executed (and how often) by the testsuite. Here's a short quickstart using
lcov:
$ CFLAGS="-fprofile-arcs -ftest-coverage" LDFLAGS="-fprofile-arcs -ftest-coverage" scons -j4 DEBUG=1
$ sudo RM_TS_USE_VALGRIND=1 RM_TS_PRINT_CMD=1 RM_TS_PEDANTIC=1 nosetests-3.4 -s -a '!slow'
$ lcov --capture --directory . --output-file coverage.info
$ genhtml coverage.info --output-directory out
The coverage results are updated from time to time here:
tests
├── test_formatters # Tests for output formatters (like sh or json)
├── test_options # Tests for normal options like --merge-directories etc.
├── test_types # Tests for all lint types rmlint can find
└── utils.py # Common utilities shared amon tests.
A template for a testcase looks like this:
from nose import with_setup
from tests.utils import *
@with_setup(usual_setup_func, usual_teardown_func)
def test_basic():
create_file('xxx', 'a')
create_file('xxx', 'b')
head, *data, footer = run_rmlint('-a city -S a')
assert footer['duplicate_sets'] == 1
assert footer['total_lint_size'] == 3
assert footer['total_files'] == 2
assert footer['duplicates'] == 1
Test should be able to run as normal user.
If that's not possible, check at the beginning of the testcase with this:
if not runs_as_root():
return
Regressions in rmlint should get their own testcase so they do not
appear again.
Slow tests can be marked with a slow attribute:
from nose.plugins.attrib import attr
@attr('slow')
@with_setup(usual_setup_func, usual_teardown_func)
def test_debian_support():
assert random.choice([True, False]):
| CFLAGS: | Extra flags passed to the compiler. |
|---|---|
| LDFLAGS: | Extra flags passed to the linker. |
| CC: | Which compiler to use? |
# Use clang and enable profiling, verbose build and enable debugging
CC=clang CFLAGS='-pg' LDFLAGS='-pg' scons VERBOSE=1 DEBUG=1
| DEBUG: | Enable debugging symbols for rmlint. This should always be enabled during
development. Backtraces wouldn't be useful elsewhise. |
|---|---|
| VERBOSE: | Print the exact compiler and linker commands. Useful for troubleshooting build errors. |
| --prefix: | Change the installation prefix. By default this is /usr, but some users
might prefer /usr/local or /opt. |
|---|---|
| --actual-prefix: | |
This is mainly useful for packagers. The rmlint binary knows where it
is installed (which is needed to set e.g. the path to the gettext files).
When installing a package, most of the time the build is installed to
a local test environment first before being packed to /usr. In this
case the --prefix would be set to the path of the temporary build env,
while --actual-prefix would be set to /usr. |
|
| --libdir: | Some distributions like Fedora use separate libdirectories for 64/32 bit.
If this happens, you should set the correct one for 64 bit with
--libdir=lib64. |
| --without-libelf: | |
Do not link with libelf, which is needed for nonstripped binary
detection. |
|
| --without-blkid: | |
Do not link with libblkid, which is needed to differentiate between
normal rotational harddisks and non-rotational disks. |
|
| --without-json-glib: | |
Do not link with libjson-glib, which is needed to load json-cache files.
Without this library a warning is printed when using -C / --cache. |
|
| --without-fiemap: | |
Do not attempt to use the FIEMAP ioctl(2). |
|
| --without-gettext: | |
Do not link with libintl and do not compile any message catalogs. |
|
All --without-* options come with a --with-* option that inverses its
effect. By default rmlint is built with all features available on the
system, so you do not need to specify any --with-* option normally.
| install: | Install all program parts system-wide. |
|---|---|
| config: | Print a summary of all features that will be compiled and what the environment looks like. |
| man: | Build the manpage. |
| docs: | Build the onlice html docs (which you are reading now). |
| test: | Build the tests (requires $ USE_VALGRIND=1 nosetests # or nosetests-3.3, python3 needed.
|
| xgettext: | Extract a gettext |
| dist: | Build a tarball suitable for release. Save it under
|
| release: | Same as |
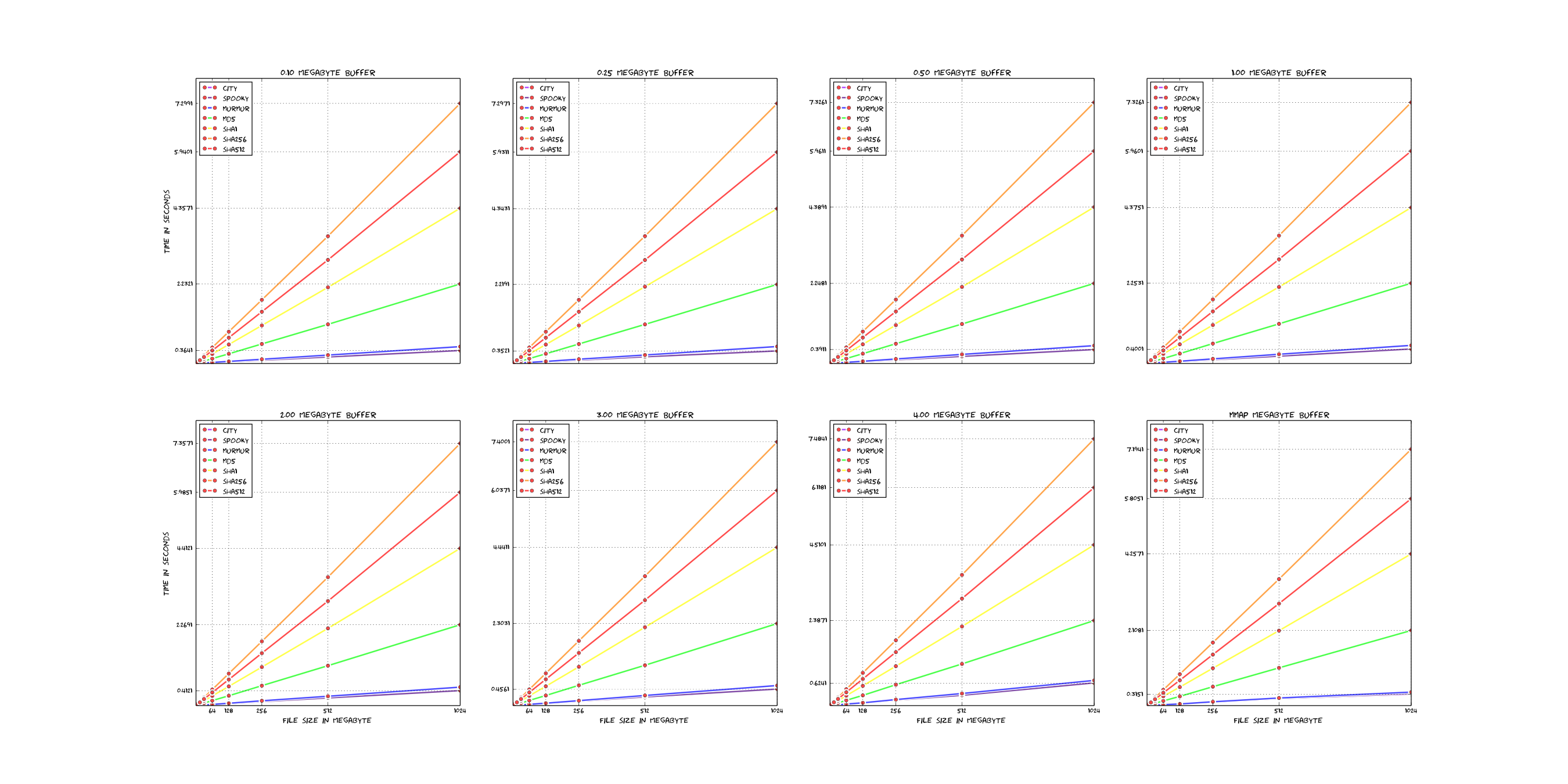
lib, the file names should be self explanatory.src/rmlint.c.docs.po.pkg/<distribution>.tests.Here is a short comparasion of the existing hashfunctions in rmlint (linear scale).
For reference: Those plots were rendered with these sources - which are very ugly, sorry.
If you want to add new hashfunctions, you should have some arguments why it is valueable and possibly even benchmark it with the above scripts to see if it's really that much faster.
Also keep in mind that most of the time the hashfunction is not the bottleneck.
For sake of overview, here is a short list of optimizations implemented in rmlint:
preadv(2) based reading for small speeedups.pthread_create are made.fiemap ioctl(2) to analyze the harddisk layout of each file, so each
block can read it in perfect order on a rotational device.--max-paranoid-mem option).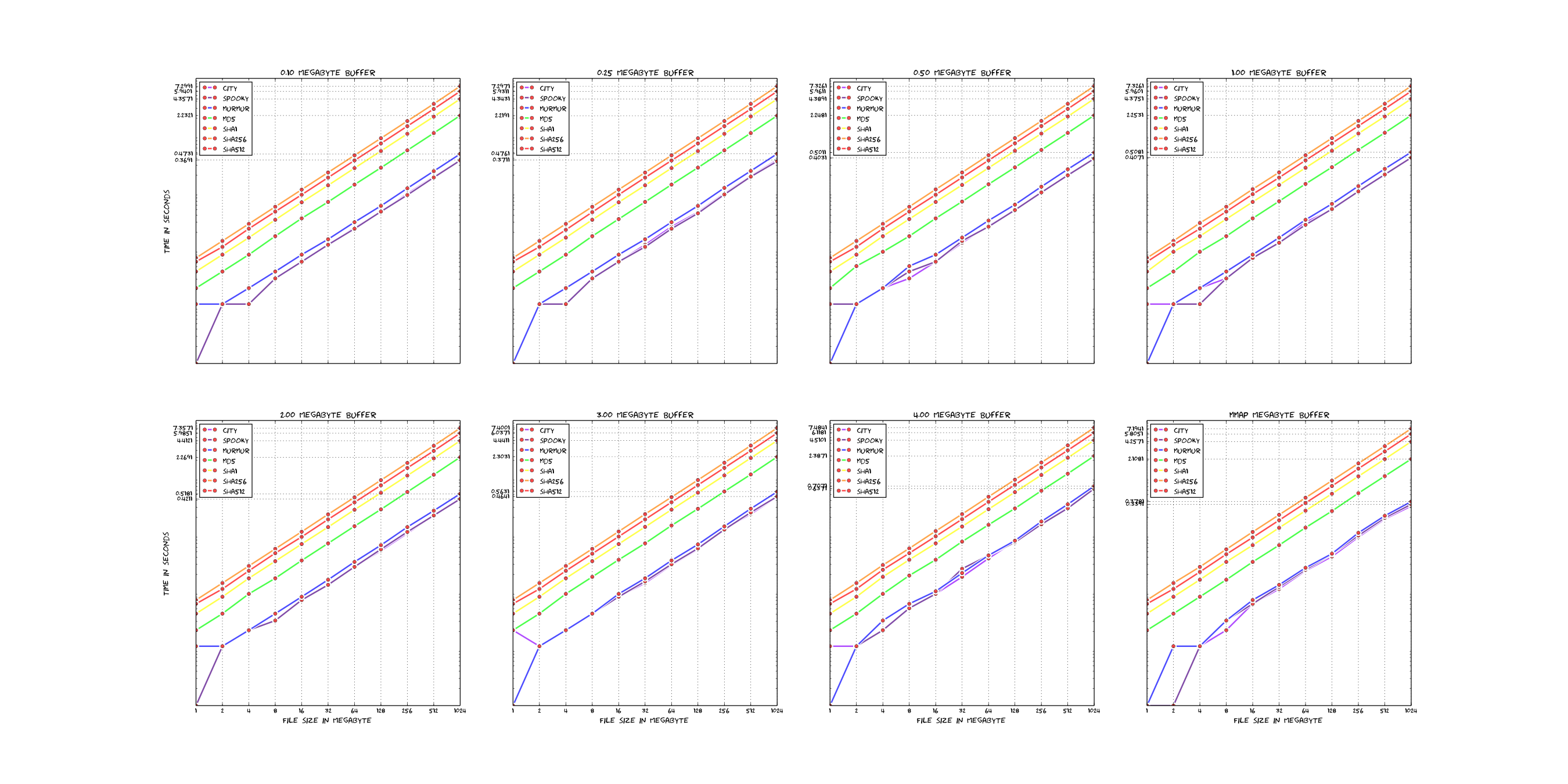{kind=link}
{kind=link}