This guide is targeted to people that want to write new features or fix bugs in rmlint.
We try to adhere to some principles when adding features:
rmlint modify the filesystem itself, only produce output
to let the user easily do it.Also keep this in mind, if you want to make a feature request.
The code is hosted on GitHub, therefore our preferred way of receiving patches is using GitHub's pull requests (normal git pull requests are okay too of course).
Note
origin/master should always contain working software. Base your patches
and pull requests always on origin/develop.
Here's a short step-by-step:
git checkout develop && git checkout -b my_feature)git commit -am "Fixed it all.")git commit --amend)git push origin my_feature)Here are some other things to check before submitting your contribution:
nosetests to find out)
Also after opening the pull request, your code will be checked via TravisCI.rmlint running okay inside of valgrind (i.e. no leaks and no memory violations)?For language-translations/updates it is also okay to send the .po files via
mail at sahib@online.de, since not every translator is necessarily a
software developer.
| CFLAGS: | Extra flags passed to the compiler. |
|---|---|
| LDFLAGS: | Extra flags passed to the linker. |
| CC: | Which compiler to use? |
# Use clang and enable profiling, verbose build and enable debugging
CC=clang CFLAGS='-pg' LDFLAGS='-pg' scons VERBOSE=1 DEBUG=1
| DEBUG: | Enable debugging symbols for rmlint. This should always be enabled during
developement. Backtraces wouldn't be useful elsewhise. |
|---|---|
| VERBOSE: | Print the exact compiler and linker commands. Useful for troubleshooting build errors. |
| --prefix: | Change the installation prefix. By default this is /usr, but some users
might prefer /usr/local or /opt. |
|---|---|
| --actual-prefix: | |
This is mainly useful for packagers. The rmlint binary knows where it
is installed (which is needed to set e.g. the path to the gettext files).
When installing a package, most of the time the build is installed to
a local test environment first before being packed to /usr. In this
case the --prefix would be set to the path of the temporary build env,
while --actual-prefix would be set to /usr. |
|
| --without-libelf: | |
Do not link with libelf, which is needed for nonstripped binary
detection. |
|
| --without-blkid: | |
Do not link with libblkid, which is needed to differentiate between
normal rotational harddisks and non-rotational disks. |
|
| --without-fiemap: | |
Do not attempt to use the FIEMAP ioctl(2). |
|
| --without-gettext: | |
Do not link with libintl and do not compile any message catalogs. |
|
All --without-* options come with a --with-* option that inverses its
effect. By default rmlint is built with all features on the system, so you
do not need to specify any --with-* option normally.
| install: | Install all program parts system-wide. |
|---|---|
| config: | Print a summary of all features that will be compiled and what the environment looks like. |
| man: | Build the manpage. |
| docs: | Build the onlice html docs (which you are reading now). |
| test: | Build the tests (requires $ USE_VALGRIND=1 nosetests # or nosetests-3.3, python3 needed.
|
| xgettext: | Extract a gettext |
| dist: | Build a tarball suitable for release. Save it under
|
| release: | Same as |
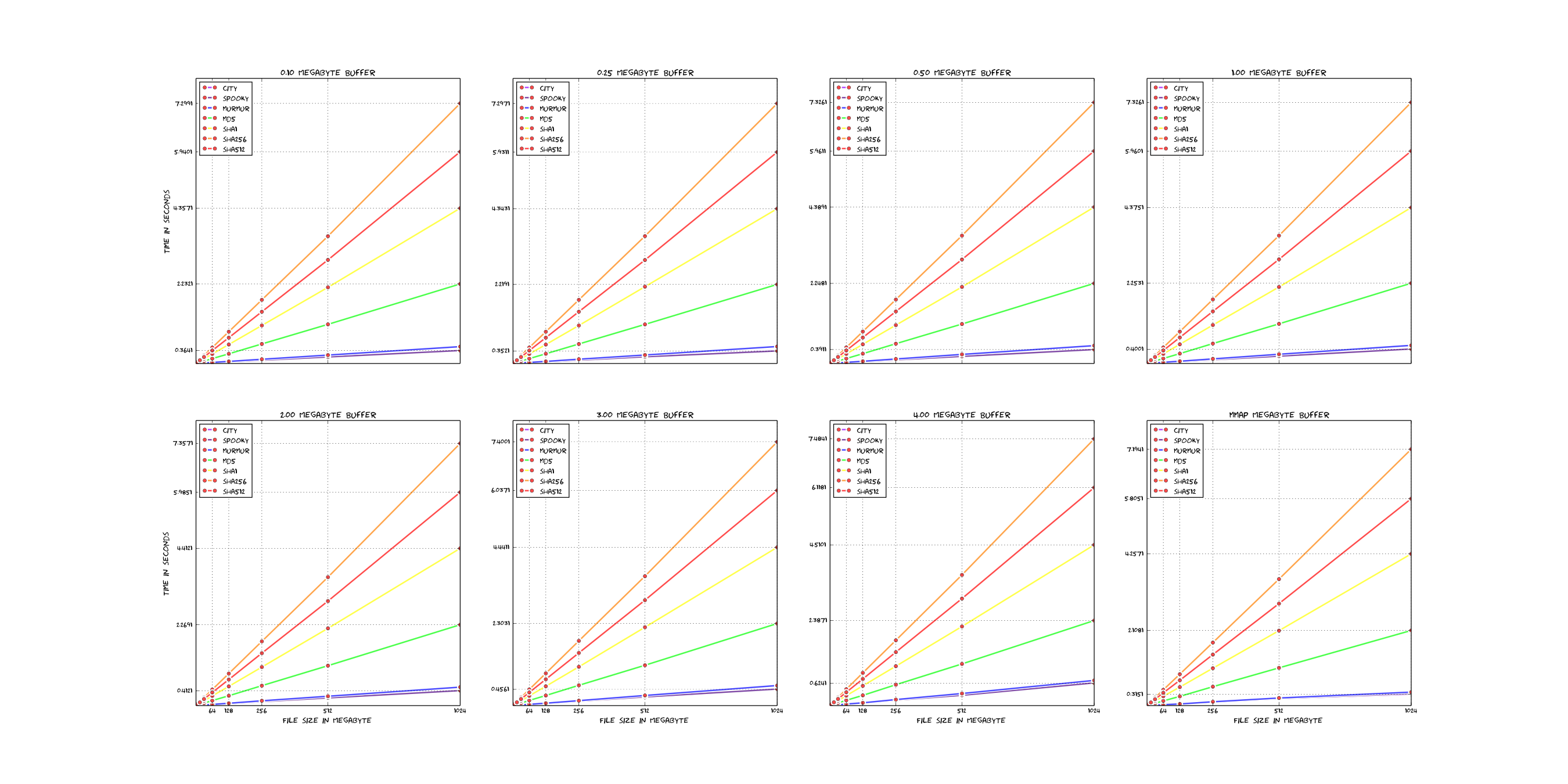
src, the file names should be self explanatory.docs.po.pkg/<distribution>.tests.Here is a short comparasion of the existing hashfunctions in rmlint (linear scale).
For reference: Those plots were rendered with these sources - which are very ugly, sorry.
If you want to add new hashfunctions, you should have some arguments why it is valueable and possiblye even benchmark it with the above scripts to see if it's really that much faster.
Also keep in mind that most of the time the hashfunction is not the bottleneck.
For sake of overview, here is a short list of optimizations implemented in rmlint:
preadv(2) based reading for small speeedups.pthread_create are made.fiemap ioctl(2) to analyze the harddisk layout of each file, so each
block can read it in perfect order on a rotational device.--max-paranoid-ram.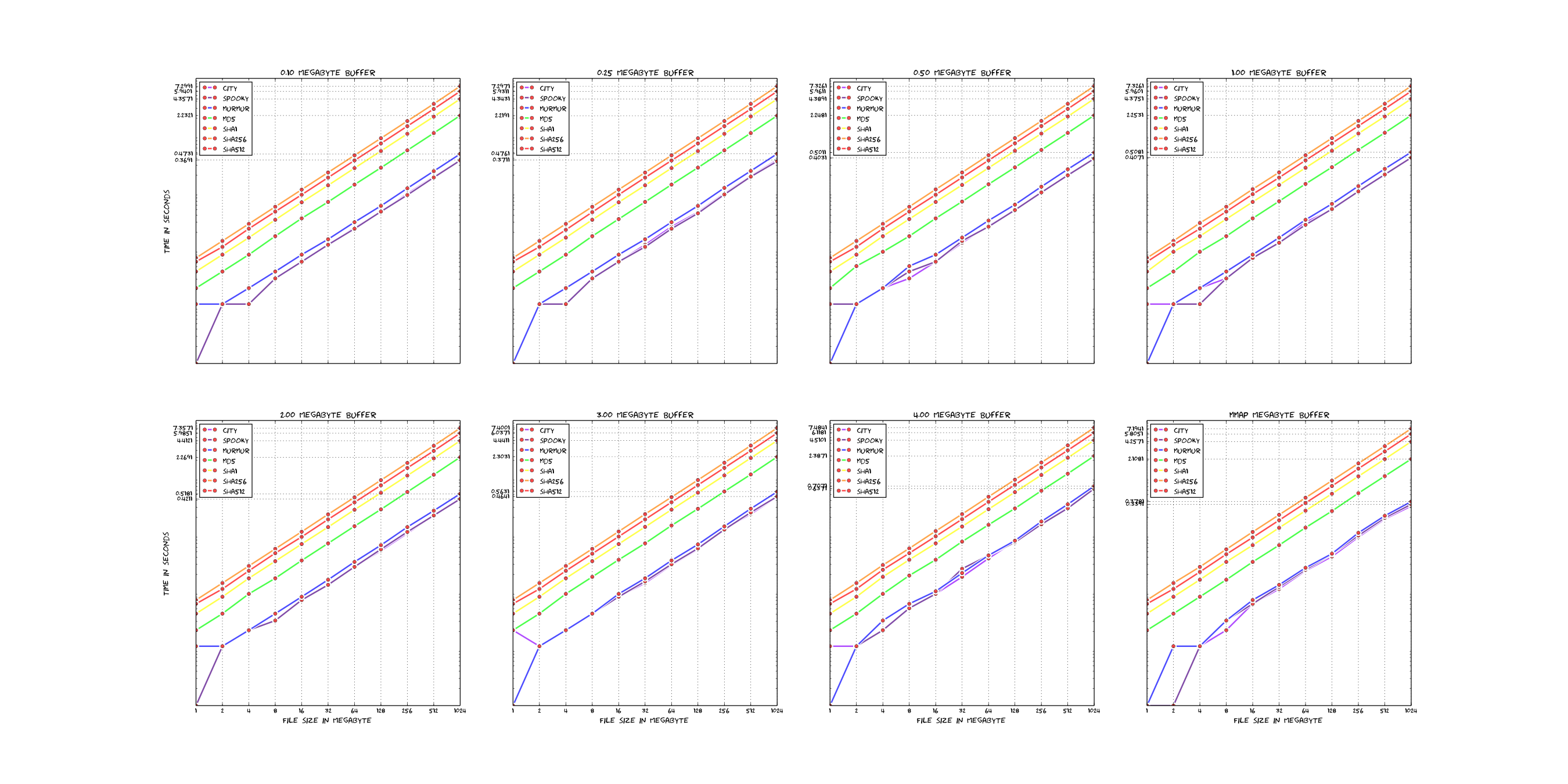{kind=link}
{kind=link}